Debugging by example: Build log liquibase error
At work on Thursday, we encountered a particularly thorny issue. I think it would be beneficial to write up a log of how I attempted to solve the problem, what went right, what went wrong, and what I could have done better.
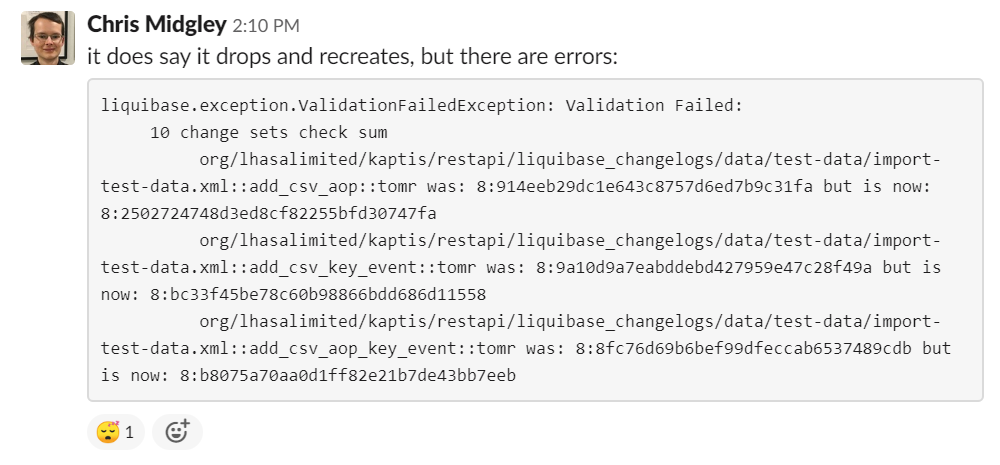
The scenario was that a build of a branch was consistently failing with a liquibase error: checksum validation was failing for the modified CSV files.
I.
I first set about trying to reproduce the problem locally. I ran the tests and they didn’t fail, so we were off to a bad start. Looking at the error message, I wanted to find out how to run the same SHA hashing algorithm liquibase was using so that I could identify what the SHA hashes corresponded to in order to help debug the problem.

I kicked off a new branch to ensure that a new database was created and a new workspace used. In the case it’s something to do with a non-fresh copy or the branch name or something, it’s good to not spend so much time on it.
The new branch failed. I rebased to flip the order of commits: 4 had nothing to do with the database and were safe in my mind, 2 had something to do with the database and 2 had something to do with those. I took the safe commits to the start and moved the others to the end. The build passed.

I rebased again to split out the CSV changes into their own commit: the functionality went in one, the test data update in the other. I expected the tests to fail, but the database rollback to be successful. I also reordered the pom change to confirm that it was uninvolved. These builds behaved as expected.

While running these full builds, I got in the situation where only one test was necessitating a rollback. We couldn’t reproduce this failure locally running only the frontend tests, but I noticed that in the build, the backend integration tests were running first, and possibly didn’t reset the data correctly for the frontend tests? I was able to reproduce the failure locally by running things slightly more like the CI server does, and fix the test for the frontend. This gave the first “green build” – not fixing the problem, but if no tests needed to roll back the database, the liquibase error wouldn’t occur and the tests would run through.
II.
At this point I’d searched the error message and found a few other people reporting the problem: one person reporting that checksums were changing for no reason with a whitespace possibly being the cause, one with a parametric issue and one cross-version change. This increased my confidence that it was a liquibase bug, though the versions didn’t match. I checked whether the versions were consistent across project – they weren’t, so I corrected that. I was optimistic!
I also looked for where the changelogs were stored. I couldn’t find any documentation on this, but the maven job implied (by lack of configuration for anywhere else) that they’d be stored in the database. Scanning through the columns, “databasechangelog” seemed likely. This let me reproduce the hashes locally (I couldn’t find any documentation on the algorithm, and md5sum of the file didn’t give me the same result). I found that the first hash was the “right” one with the changes in, but I couldn’t find the second.
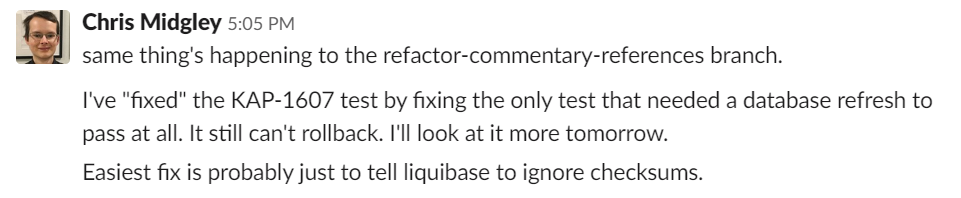
At this point, a second branch failed: this one also made changes to CSV files, and those CSV files reported checksum errors. I found out how to ignore checksums (<validCheckSum>ANY</validCheckSum>), kicked off the branch again, and went home.
III.
I didn’t feel good about this change – I still didn’t know why the checksums were changing, and ignoring errors is fundamentally a bad solution.
The builds were taking quite some time to run through (the frontend integration tests are ~20 minutes, assuming no failures), so I set about minimising that. I removed the frontend unit tests (~4 minutes) – the backend unit tests ran as part of mvn package and were a lot faster, anyway. I cut the frontend integration tests down to one test that tried to do a database rollback, just so I could check the logs and see whether the error occurred or not. Checking the logs, I saw that no backend test ever attempted a database rollback, so I did the same thing for those tests – one test that only tries to do a rollback. This lead to the first important clue: the error didn’t happen for the backend tests.
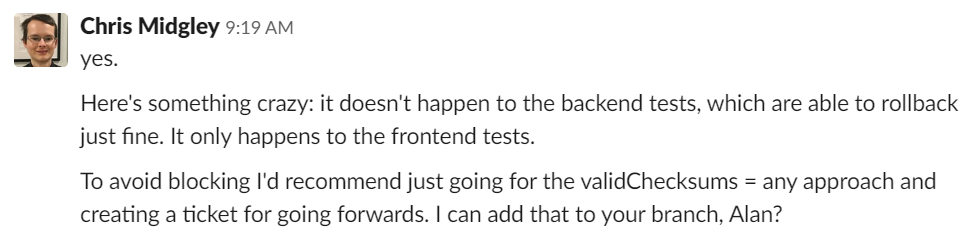
I also had the idea of checking the checksums of the CSV files in the develop branch, in case there was some contamination going on there (I was having much better ideas after sleeping on the problem). This lead to the second important clue: the second SHA hash was the hash of the CSV file in the develop branch.

The second checksum was the same as the CSV files in the develop branch! It wasn’t a liquibase problem – it was a build problem!
IV.
We had standup at 9:45, and David suggested that the docker containers weren’t correctly sharing the m2 repository. The frontend tests got the correct CSV files by having the backend install itself into the repository, then using that repository.
The backend and the frontend did use quite different mechanisms: the backend used a docker agent with an argument that mounted the volume:
agent {
docker {
image 'maven:3.6.2-jdk-11'
args "-v \$HOME/.m2:/root/.m2 --link ${KAPTIS_BACKEND}"
reuseNode true
}
}whereas the frontend used the default agent and ran a script command to make a docker image:
docker.image('maven:3.6.2-jdk-11').inside("-v \$HOME/.m2:/root/.m2 --link ${s.id}:selenium")I couldn’t see an obvious way to change them to the way that worked. I added an explicit mvn install step to the frontend tests to install the backend to the repository – I was pretty confused at this point, because the step upstream that creates the jar file doesn’t run mvn install at all, but mvn clean package -ntp -s $MAVEN_SETTINGS, so I couldn’t see how the backend CSV files were getting into the repository at all.

This didn’t work, but I noticed separately that the frontend tests were running the tests in a very different way to the backend tests. This gave me an idea to reproduce the problem locally: drop and recreate the database, run the backend to populate the database, run the backend and frontend tests from the commandline (normally they’re run in IntelliJ). This worked: I could now check fixes locally. Taking advantage of the speedier develop time, I fixed the command and committed it.
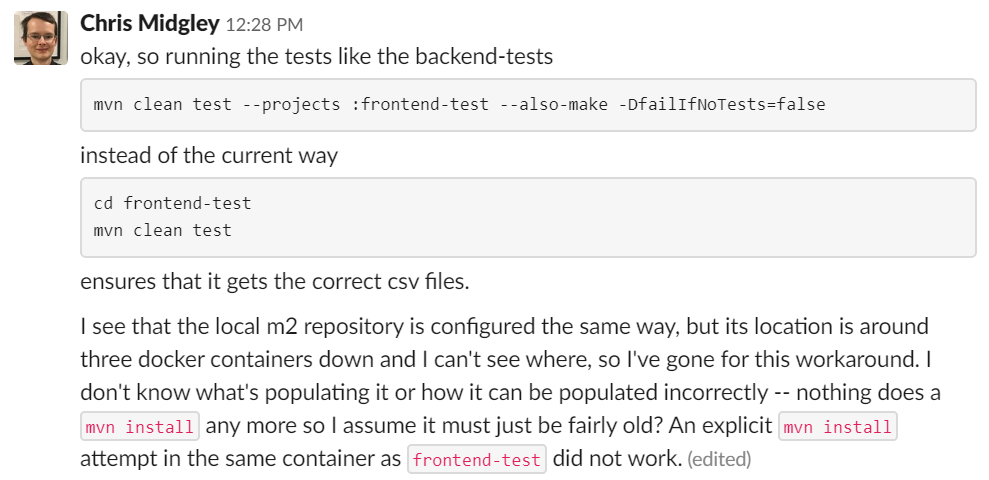
When modifying the frontend tests to run the same as the backend tests, I hit the same problems we had with the backend tests: --also-make runs the unit tests of the things it builds, which you don’t want. You can get around this by using --activate-profiles to run a profile that doesn’t exist in the backend, but then it’ll fail unless you also use -DfailIfNoTests=false. I remembered this because I’d worked on these bugs before, but I don’t think we recorded them anywhere.
V
I lost a lot of time going down dead-ends. Some of these were beneficial, as when I fixed the backend test data rollback, but most weren’t. I think an ideal debugging procedure would look like:
- create a minimum build which runs no unit tests and one backend and one frontend integration test, both of which only roll the database back
- reproduce the problem locally
- note that the error occurs with the frontend tests but not the backend
- change the build steps to run the frontend tests the same way the backend tests are being run, and confirm this works locally
- commit and push
I didn’t minimise the build time as I wanted to rush ahead with solving the problem. I think this would have paid off even had I been able to solve the issue almost immediately.
When I minimised the build for the first time, I didn’t include the backend tests. I knew we’d seen the issue on the frontend tests, so I wanted to focus on that. I eventually included the backend tests only when I noticed that we weren’t seeing the issue on the backend tests because they never rolled back at all, and I wanted to see whether it was present there as well (I was expecting it to be).
I wasn’t able to reproduce the problem locally at first. The CI build does some fairly complicated things that are tricky to do locally (docker files with their own network, dockerized selenium standalone with custom configuration, have to be careful with the commands run: drop database, create database, start app, run tests with commandline command), so I avoid doing everything unless I feel I have to. It would be worth putting some time into making this easy to do locally – the immediate downside of this is that the build runs as a Jenkinsfile, so it likely wouldn’t be kept up-to-date with the local version.

We could have avoided this problem type entirely by having the test data as part of the backend and frontend test projects, and deleting and inserting it when running the tests: it doesn’t have to be the same in both, and it doesn’t have to be owned by the backend project. We could probably save some time by using raw SQL instead of liquibase and CSV files to do the rollback.